
Redgate SQL Provision, SQL Clone, Data Masker Part1
Table of Contents
A long time ago in a galaxy far, far away…
This post is over 24 months old, that is an lifetime in tech! Please be mindful of that when reading this post, young Padawan, as it could be outdated. I try to keep things up to date as much as possible. If you think something needs updating, please let me know in the comments.
First Look at Data Provision
I managed to get some time with Redgate at SQLBits XVIII and was interested in seeing a demo of SQL Provision. I have watched Redgate promoting Compliant Database DevOps heavily over the past 6 months and was intrigued to see their latest product in action. It didn’t disappoint!
Compliant Database Development
Before moving into consultancy I was a tech lead responsible for multiple reporting solutions supported by a multi-tenant data warehouse solution. One of the areas that gave me the biggest headaches was putting together a fluid software development lifecycle (SDLC).
Defining an SDLC at the reporting level was relatively straightforward. We would sync the production build to development, make changes in a developer-specific instance of a report, deploy changes through to test then through to production. Nice and easy.
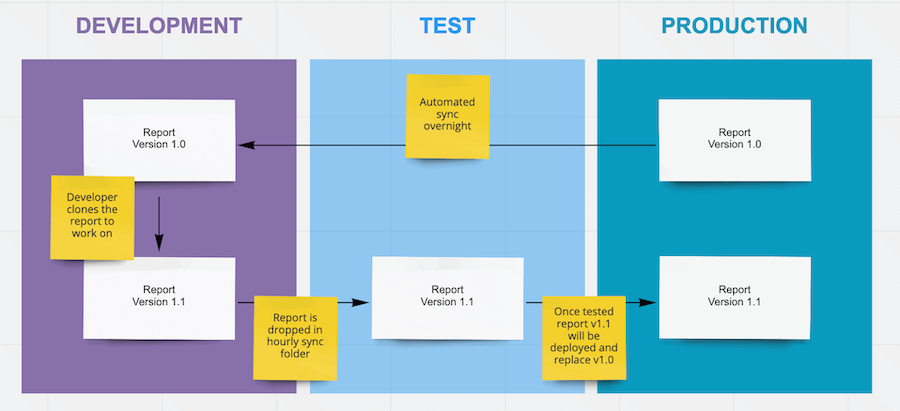
Trying to adopt a similar process at the database level is a much bigger challenge. Identifying changes and shipping them between environments is complex enough. Redgate provide some great tools in their SQL Toolbelt for identifying, packaging and deploying change and SQL Change Automation enhances your SDLC by automating those processes.
But the problem more often than not, is data.
Chances are you’re handling some form of sensitive data. Whether it’s customer data, or company data, there is likely to be one or more subject matters in your data warehouse that are governed by regulations or company policies. Back then, I was contending with company policies and the Data Protection Act (DPA) but data is even more tightly regulated now by the introduction of the General Data Protection Regulation (GDPR).
Adhering to those policies more often than not means hindering your development team in some shape or form. My development team were no different and I had to contend with frustrated developers who wanted better data. There may be a number of reasons for poor data quality in development;
A lack of rich, production-like data in source systems
Non-production source systems don’t always hold perfect datasets. You may encounter a data set that sufficiently proves that the system works, but that dataset might be heavily scrambled and doesn’t satisfy every process, or sometimes even loses referential integrity as a result of scrambling. Chances are it’ll only be a small subset of your production dataset too so testing at scale is also a challenge.
Competing development tracks not aligned with ours
If development are making changes to source systems or running tests for specific test plans, this might further compound your ability to get the data you need from these systems.
Equally, there may be times where database development and report development tracks aren’t aligned and so there may be a need to develop and test database development changes without impacting your reporting development track.
A lack of space in development environment for multiple builds
The issue with development environments is it’s just not production! More often than not, development environments are stripped back and disk space is scarce so the idea of running multiple versions of your database with complete datasets in is inconceivable.
A lack of dedicated testers
One counter to a lack of production data is dedicated testers. They are such a valuable resource! Testers can produce test plans and test data specifically to test your changes. There might have been a tester at one point but yeah we got rid of them / we didn’t replace them / they got reallocated and so developers end up taking on the role of testers too. This often results in this becoming another gap because if developers wanted to be testers, they’d be testers right?
A lack of rich, production-like data for report developers
Report developers long for production data. There is a constant debate over this and whilst it’s a healthy debate to be had, there is a case for having close-to-real data to develop and test against. Test data can be produced to prove processes but to do that at scale is time consuming. Certainly, when reports are performing cross-portfolio analysis or deep analysis into multiple scenarios, to put that sort of data together will take time and unfortunately, quite often demand is such that time is the one thing you don’t have.
Difficult to reflect modern day development process
Shared database development (where all developers develop on the same database) is a complicated thing. Often this approach is done out of necessity but whether it is competing changes, or inadvertently releasing someone else’s change it comes with its own risk. As a development team you have to work really hard on process and controls to ensure you don’t push changes inadvertently or overwrite some else’s change. Wouldn’t it be great if you all had your own version of DEV to develop on??
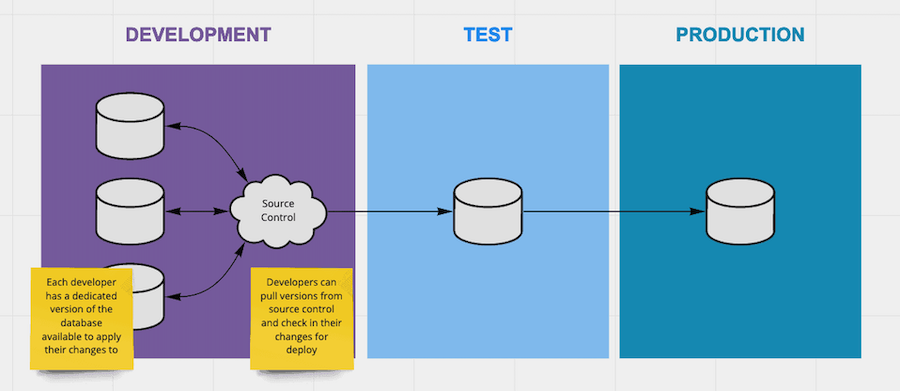
Production data cannot be placed in a development environment
And here is the deal breaker. Ultimately, you can’t use production data in development environments if you have sensitive data to contend with. I am not going to go focus on GDPR here, there is plenty of discussion out there on it. Even if you had the space available to you, you are going to have a hard time convincing anyone to allow you to restore a production database to development even if you promise to scramble it. And even if you did, the time spent restoring one or more versions of the database and then running update processes just doesn’t sound very appealing. There is gotta be a better way right?
Enter SQL Provision
SQL Provision goes a long way to addressing these issues! I had a very slick demo of the product at SQLBits and I was extremely impressed by what I saw, but I wanted to put my own test together to see how good it really was.
At a very high level, SQL Provision creates an image of your source database (either via a backup or via direct access to a database) and is then able to create multiple clones from that initial image. Each clone has an independent data file meaning your team can develop in parallel and test in parallel. They can even roll back to the initial clone independent of each other. During image creation SQL Provision will run data masking rules in order to protect sensitive data, clones will then be made available with the masked data. Equally, each developer can make changes to their dataset independent of others, and only those changes will be stored directly in the clone’s data file meaning the footprint for multiple clones is considerably smaller (initially anyway - if you change the entire database then you’re clone will get bigger).
The best part is it is pretty intuitive to put together too! I pulled up a VM and had clone deployed in a few hours!
I am not going to go through system requirements, installing any of the tools / agents or permissions, check out Redgate docs for that. I am going to be making use of the AdventureWorksDW2017 which is available on GitHub. The restored database has a footprint of ~256MB. For the purpose of the demo, I am going to focus on masking dimCustomer and then provision a copy of the database for each of my developers.
Preparing the data masking rules
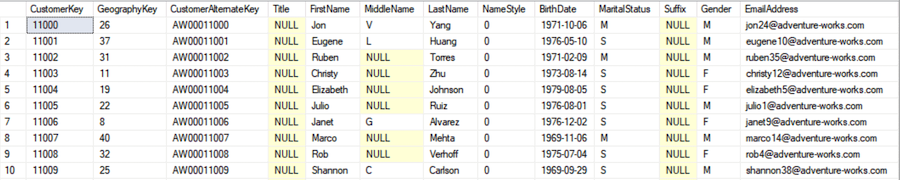
Here is the first 10 rows from dimCustomer. As you can see there is some fields that we will need to mask before making this database available in development.
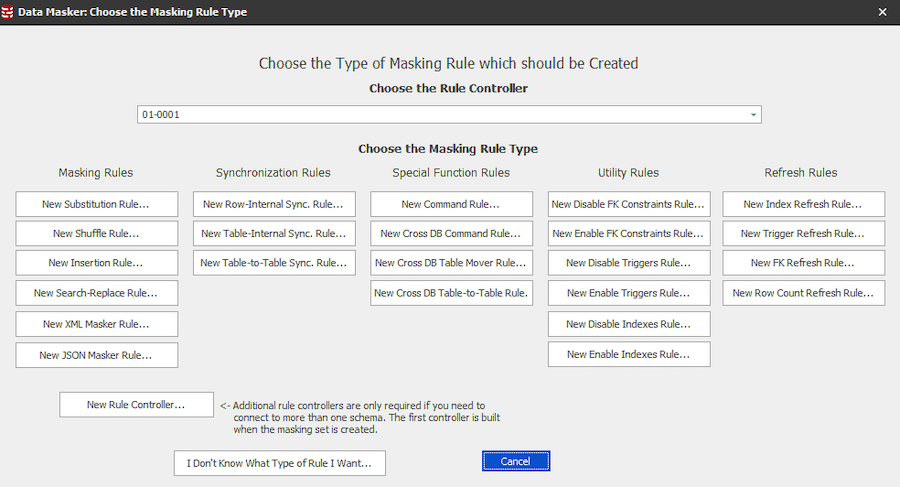
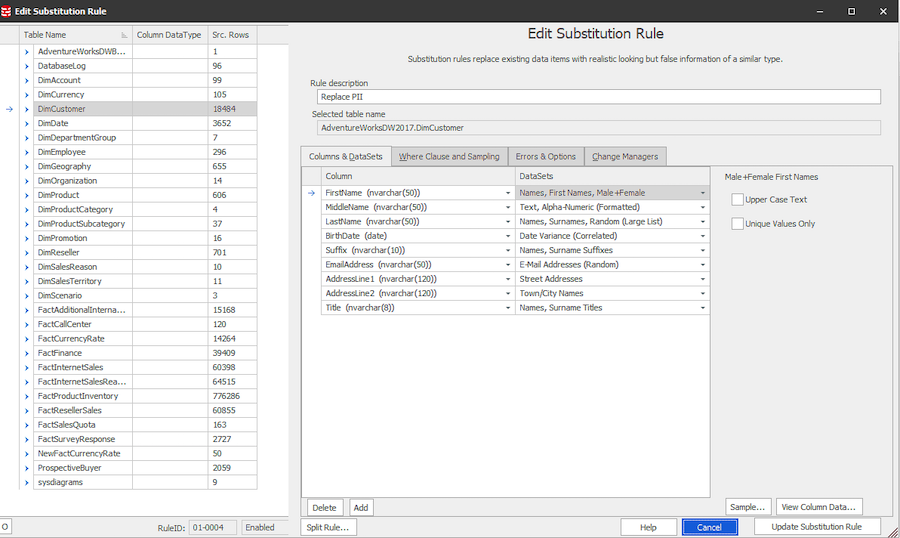
So firstly, we need to set up some masking rules using Data Masker. There is a load of masking rules to choose from and if you’re not sure what sort of rule you want, Redgate have put together a handy page detailing what each of them do.
We are simply going to substitute the data for now. Once you’ve set a masking rule you will be presented with an object list on the left where you choose the columns you wish to form part of this rule. You can choose from a number of pre-defined datasets that can be applied to each column. If there isn’t a suitable dataset for your needs, you can roll your own user defined data using RegEx.
Creating an image
Next we move onto SQL Clone which is managed through a web interface. The initial page is a dashboard of your current configuration and each step is intuitively laid out to the left of the screen.
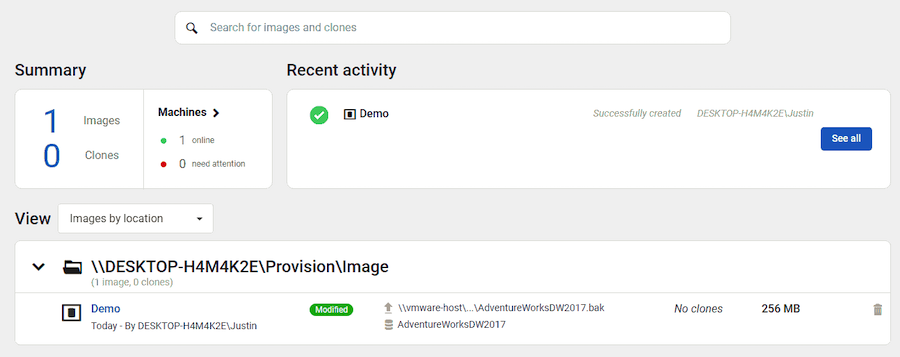
We need to create an image which acts as the primary dataset for the clones. The image requires a server to temporarily host the backup on (in order to apply masking rules) and a file share where it will host the completed image. There is a few settings to configure which are simply defining those locations.
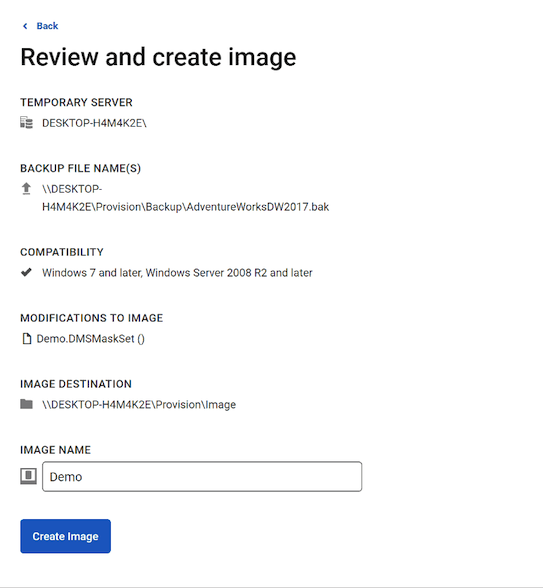
Depending on the size of your database and the number of rules you’ve configured, this process may take some time to complete since it is restoring the database and running the rules against that database. Once complete, SQL Clone’s webpage will inform you that it has completed.
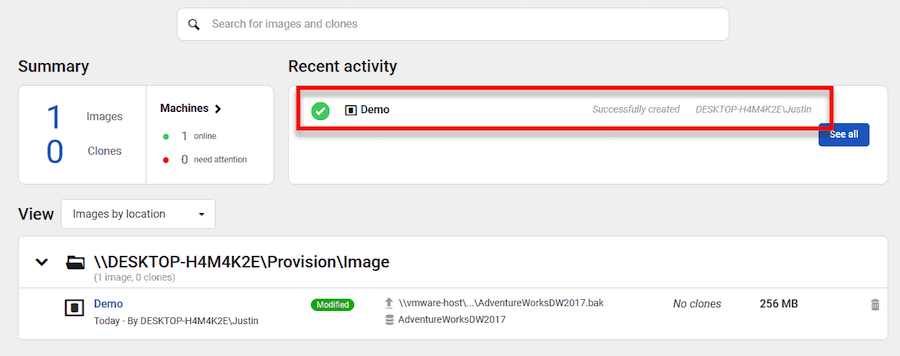
Creating clones
Once complete you are ready to clone! From here, you pick the image you wish to clone (since you can have multiple images hosted at once) and then set the name of the clone.
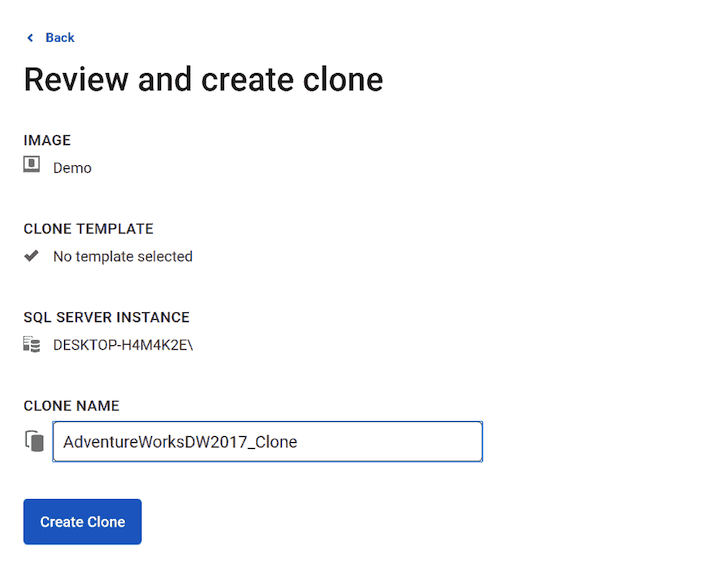
This takes a fraction of the time it took to provision the initial image since it is just creating a clone of the original image. SQL Clone will provide you feedback that it has completed.

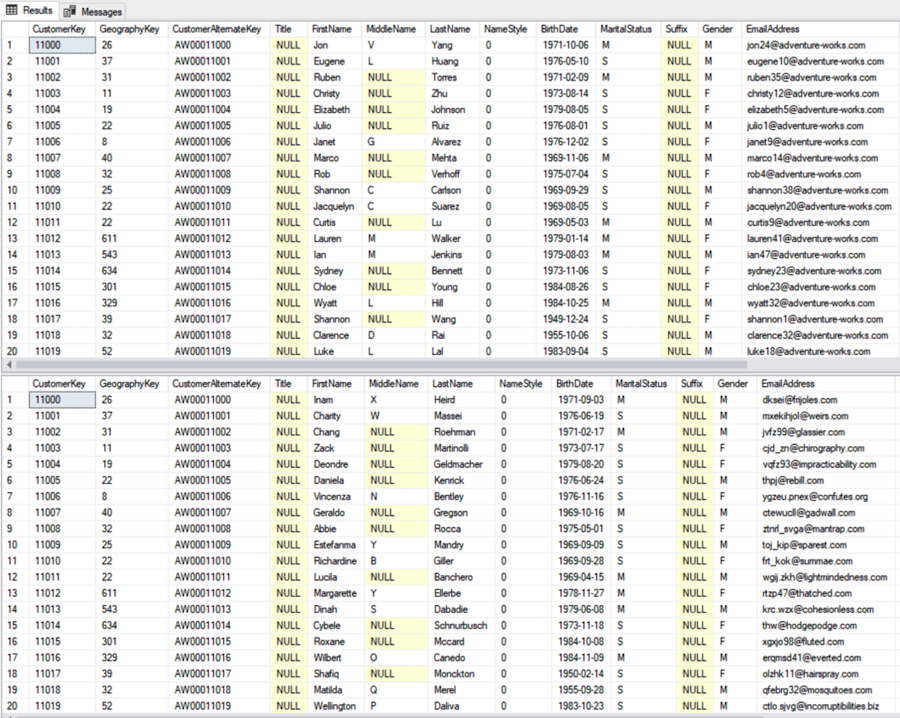
And there you have it! With very little effort I have created a cloned copy of the AdventureWorks Database. Here you can see two queries running against the original and cloned image of AdventureWorks and as you can see our customer data has been masked (note, I hadn’t refreshed my object explorer in the demo, but the clone is there!).
Redgate have also provided the ability to construct Powershell scripts to manage both the image creation and clone deploy meaning with a few lines of code you can provision and deploy several copies of your database in one execution.
Timings and footprint
The process of provisioning a masked image took ~49 seconds. That included restoring the database, masking the data and provisioning the base image. The footprint of that base image is ~256MB whereas each clone took ~2 seconds to deploy and all 4 clones have a total footprint of ~176MB! Redgate do suggest that each clone begins at around the 40MB mark.
As a follow up, I am going to clone a much larger database - WideWordImporters - and see how it performs with a database with a much more substantial footprint.
Summary
I am really impressed with this product! When I tried to design a better process for my development team to work with there were so many obstacles and whichever path we chose there was always compromise or dead ends that meant we just couldn’t satisfy every requirement. This solution gives you considerable flexibility to construct a defined masking rule set and provision an image all of which can be secured away from development users meaning you can clearly demonstrate compliance with data regulations. Cloned copies of the database can then be deployed on a schedule, or called by the developer on demand and are available within a few seconds.
From install, it took me under two hours to get the process up and running with a rudimentary masking rule set, it’s really intuitive to get started but you can see there’s some incredible power available within the vast array of masking rules available to you.
All scripts used for the demos can be found on Github.

#mtfbwy